
kubeadm搭建多个master节点的k8s集群
环境规划
虚拟机环境是ProxmoxVE,当然你也可以用VMware或VirtualBox。
另外:最好有科学上网的环境,操作过程中尽量把需要科学上网的源都改成了国内源,但是并不是所有的镜像都有国内源。
虚拟机操作系统:Debian11,从Debian官网下载的iso镜像,最小化安装,不包含图形界面。
虚拟机配置:
主机名 IP地址 配置 节点角色 k8s-master1 192.168.32.204 2核2G master k8s-master2 192.168.32.205 2核2G master k8s-master3 192.168.32.206 2核2G master k8s-worker1 192.168.32.207 2核2G worker k8s-worker2 192.168.32.208 2核2G worker k8s-worker3 192.168.32.209 2核2G worker VIP(虚拟IP):192.168.32.250
3个master节点,主要作用是使master节点高可用,实际工作过程中只有一个master在发挥作用,另外两个只是备份。在工作master节点出现问题时,通过IP地址漂移将master节点的IP地址自动漂移到其它的master节点达到高可用的目的。因此每个master除了需要有一个自己的IP,还需要有一个可以在三个节点中自动漂移的VIP。
环境准备-所有节点
虚拟机环境安装可以先在一个虚拟机上准备好环境,然后直接克隆
在开始之前当然是先配置国内源,然后更新下系统,这个不多说了。
关闭swap,需要两步操作
修改/etc/fstab文件,注释掉挂载swap分区的指令,然后重启

在最新版的debian系统中,就算操作完上一步,还是无法关闭swap。还得屏蔽掉systemd的服务,然后重启

重启之后检查一下swap分区是否成功关闭:

Swap total 为0 说明已经关闭
安装容器运行时:参考Docker官方文档
# 首先安装一些依赖软件 apt-get install ca-certificates curl gnupg # 添加docker仓库的GPG key mkdir -m 0755 -p /etc/apt/keyrings curl -fsSL https://download.docker.com/linux/debian/gpg | gpg --dearmor -o /etc/apt/keyrings/docker.gpg # 添加docker仓库,注意这里把docker官方仓库地址,修改为了ustc的国内地址 echo \ "deb [arch="$(dpkg --print-architecture)" signed-by=/etc/apt/keyrings/docker.gpg] https://mirrors.ustc.edu.cn/docker-ce/linux/debian \ "$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | \ tee /etc/apt/sources.list.d/docker.list > /dev/null # 安装容器运行时 apt update apt install containerd.io # 锁定版本,防止系统更新时更新版本导致兼容问题 apt-mark hold containerd.io说明:这里不需要安装所有的docker环境,只需要一个containerd.io的包。这还需要了解一下docker和k8s之间的爱恨情仇的小历史:
- 2014年k8s刚刚诞生,Docker如日中天已成为容器的代名词,所以k8s自然选择了依附Docker;
- 2016年k8s已经相对成熟,加入了CNCF,成为了第一个CNCF托管项目。然后引入了CRI(Container Runtime Interface),提供了一个统一的容器运行时接口,和docker完全不兼容。意思很明显,想要提供一套标准接口,自己来掌握标准的制定。
- 但是这个时候Docker仍然是最火的容器,因此k8s也提供了一个折中的方案,在kubelet和docker之间加入了一个适配器,把docker的接口转换成cri接口,即dockershim。
- 随着k8s的逐渐强大,docker也只得“断臂求生”,把Dcoker Engine拆分成了多个模块,其中的Docker Daemon部分捐献给了CNCF,符合CRI标准,就是现在的containerd。
- 所以docker本身也是通过Docker Engine调用containerd,外部与CRI不兼容。
- k8s操作容器可以通过dockershim调用docker的接口,也可以直接通过CRI调用containerd的接口。
- 2020年k8s1.20版本的时候宣布弃用docker,在1.24版本时候彻底弃用了docker,本质上弃用的只是dockershim,底层调用的还是相同的containerd。
配置containerd
将containerd的配置文件置为默认:
containerd config default | tee /etc/containerd/config.toml然后修改/etc/containerd/config.toml:
# 搜索并修改sandbox_image地址,改为国内地址 sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.6" # 修改Cgroup类型为systemd SystemdCgroup = true重启containerd
systemctl restart containerd安装kubeadm、kubelet、kubectl,参考 官方文档
# 安装依赖包 apt install -y apt-transport-https ca-certificates curl # 导入google cloud公开签名(可能需要科学上网) curl -fsSLo /etc/apt/keyrings/kubernetes-archive-keyring.gpg https://packages.cloud.google.com/apt/doc/apt-key.gpg # 添加kubernetes仓库,这里把官方源改成了国内源 echo "deb [signed-by=/etc/apt/keyrings/kubernetes-archive-keyring.gpg] https://mirrors.ustc.edu.cn/kubernetes/apt kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list安装:
apt update apt install -y kubelet kubeadm kubectl # 锁定版本 apt-mark hold kubelet kubeadm kubectl修改iptables配置
cat <<EOF | tee /etc/modules-load.d/k8s.conf overlay br_netfilter EOF cat <<EOF | tee /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward=1 EOF sysctl --system
节点配置
上面的环境准备完成后,可以关闭虚拟机了,然后根据这个虚拟机克隆出另外5个:

每个节点按照之前的规划,修改好主机名和静态的IP地址,这里展示只展示k8s-master1的操作:
使用以下命令修改主机名,修改完之后别忘了修改/etc/hosts文件中的主机名
hostnamectl set-hostname k8s-master1修改静态IP:/etc/network/interfaces
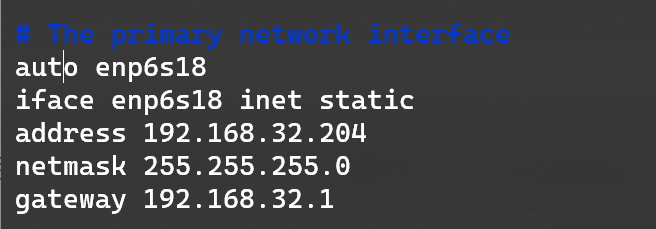
最后重启生效。
master节点配置
创建kube-vip的静态pod文件:参考kube-vip文档 。 这一步是为了实现master节点的高可用,如果只有一个master节点,忽略这一步
文档中提供了两种方案:keepalived+haproxy,kube-vip,我们使用更简单的kube-vip。
我们最终的目的只需要一个kube-vip.yaml文件,生成这个文件的过程稍微有点复杂,这里提供一个生成好的。
apiVersion: v1 kind: Pod metadata: creationTimestamp: null name: kube-vip namespace: kube-system spec: containers: - args: - manager env: - name: vip_arp value: "true" - name: port value: "6443" - name: vip_interface value: enp6s18 - name: vip_cidr value: "32" - name: cp_enable value: "true" - name: cp_namespace value: kube-system - name: vip_ddns value: "false" - name: vip_leaderelection value: "true" - name: vip_leaseduration value: "5" - name: vip_renewdeadline value: "3" - name: vip_retryperiod value: "1" - name: vip_address value: 192.168.32.250 - name: prometheus_server value: :2112 image: ghcr.io/kube-vip/kube-vip:v0.5.10 imagePullPolicy: Always name: kube-vip resources: {} securityContext: capabilities: add: - NET_ADMIN - NET_RAW volumeMounts: - mountPath: /etc/kubernetes/admin.conf name: kubeconfig hostAliases: - hostnames: - kubernetes ip: 127.0.0.1 hostNetwork: true volumes: - hostPath: path: /etc/kubernetes/admin.conf name: kubeconfig status: {}以上文件需要根据自己的环境进行修改:
- vip_interface: 改成你自己的网卡名字,这个网卡是与外部通信的网卡,通过
ip addr可以查看 - vip_address:改成你自己的VIP地址
最终这个文件要复制到:/etc/kubernetes/manifests/kube-vip.yaml,位于这个目录的yaml文件在集群启动时会自动应用。
- vip_interface: 改成你自己的网卡名字,这个网卡是与外部通信的网卡,通过
创建初始化集群的配置文件master-init.yaml
# master init apiVersion: kubeadm.k8s.io/v1beta3 kind: InitConfiguration nodeRegistration: criSocket: unix:///var/run/containerd/containerd.sock --- # 会自动应用到全局 apiVersion: kubeadm.k8s.io/v1beta3 kind: ClusterConfiguration kubernetesVersion: stable controlPlaneEndpoint: 192.168.32.250 imageRepository: registry.aliyuncs.com/google_containers --- # 所有节点添加的配置 apiVersion: kubelet.config.k8s.io/v1beta1 kind: KubeletConfiguration cgroupDriver: systemdkubernetesVersion: 要部署的kubernetes的版本,需要填写完整的版本号,stable表示最新的稳定版,截止到这篇文章是v1.26.3 。查看所有版本
controlPlaneEndpoint: 控制平面地址,即VIP地址,也可以是域名的形式
imageRepository: 镜像仓库地址
使用上面的配置文件创建集群
在创建集群之前,需要先通过科学上网把kube-vip的镜像拉下来,containerd的管理工具是crictl,在之前安装环境的时候,这个工具已经自动装好了。
crictl --runtime-endpoint unix:///run/containerd/containerd.sock pull ghcr.io/kube-vip/kube-vip:v0.5.10初始化集群:
kubeadm init --upload-certs --config master-init.yaml初始化成功之后,会提示如何配置环境变量来使用集群,并且给出了加入master节点和加入worker节点的指令(包含了需要用到的token和cert),如下图所示:

因为以后主要用普通用户操作k8s集群,所以按照上面的提示,切换成普通用户(这个普通用户需要有sudo的权限),然后执行:
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config另外查看网卡信息,会看到多了一个ip地址,即我们设置的VIP:

加入master节点
可以直接使用上一步的初始化完成之后的提示,在master节点上直接执行,这里是通过配置文件来执行。
登录其它的master节点:修改好 主机名、IP地址、添加好kube-vip.yaml、下载好kube-vip的镜像。
然后创建一个master-join.yaml文件,内容如下
# 所有节点添加的配置 apiVersion: kubelet.config.k8s.io/v1beta1 kind: KubeletConfiguration cgroupDriver: systemd --- # master join apiVersion: kubeadm.k8s.io/v1beta3 kind: JoinConfiguration discovery: bootstrapToken: token: [上一步初始化完成提示的token] apiServerEndpoint: 192.168.32.250:6443 caCertHashes: - sha256:[上一步初始化完成提示的sha256] controlPlane: certificateKey: [上一步初始化完成提示的cert]通过配置文件加入:
kubeadm join --config master-join.yaml
加入worker节点
可以直接使用上一步的初始化完成之后的提示,在worker节点上直接执行,这里是通过配置文件来执行。
登录其它的worker节点:修改好 主机名、IP地址。这里不需要kube-vip.yaml,也不需要下载kube-vip的镜像
然后创建一个worker-join.yaml文件,内容如下
# 所有节点添加的配置 apiVersion: kubelet.config.k8s.io/v1beta1 kind: KubeletConfiguration cgroupDriver: systemd --- # worker join apiVersion: kubeadm.k8s.io/v1beta3 kind: JoinConfiguration discovery: bootstrapToken: token: [上一步初始化完成提示的token] apiServerEndpoint: 192.168.32.250:6443 caCertHashes: - sha256:[上一步初始化完成提示的sha256]通过配置文件加入:
kubeadm join --config worker-join.yaml
安装网络插件cilium
经过之前的操作,我们已经搭建好了一个k8s集群,但是此时的集群还不能使用,还需要在集群里安装一个网络插件才能真正使用起来。
在任意一个master节点查看node信息,可以看到status都是NotReady。

这里我们选择的网络插件是cilium,因为安装起来非常简单,只需两步,参考:官方文档,但是在下载cilium的时候可能需要科学上网
# 首先下载cilium命令行工具
CILIUM_CLI_VERSION=$(curl -s https://raw.githubusercontent.com/cilium/cilium-cli/master/stable.txt)
CLI_ARCH=amd64
if [ "$(uname -m)" = "aarch64" ]; then CLI_ARCH=arm64; fi
curl -L --fail --remote-name-all https://github.com/cilium/cilium-cli/releases/download/${CILIUM_CLI_VERSION}/cilium-linux-${CLI_ARCH}.tar.gz{,.sha256sum}
sha256sum --check cilium-linux-${CLI_ARCH}.tar.gz.sha256sum
sudo tar xzvfC cilium-linux-${CLI_ARCH}.tar.gz /usr/local/bin
rm cilium-linux-${CLI_ARCH}.tar.gz{,.sha256sum}
# 然后执行安装
cilium install安装完之后再次查看集群节点状态:
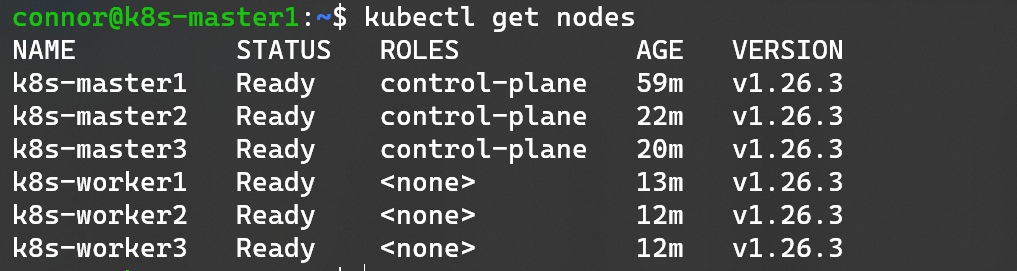
结束
到此为止,一个基本的k8s集群环境就搭建好了。
但是如果要部署项目,还需要ingress-nginx(七层代理)、nfs-provisioner(自动分配nfs类型的pv)、cert-manager(自动部署https证书)等插件。
这些在以后的博客中会慢慢总结。